Doomslug vs PBFT, Tendermint, and Hotstuff
In this blog post, we will see how Doomslug, our new block production technique, compares to PBFT, Tendermint, and Hotstuff. We will also dig relatively deep into how PBFT, Tendermint and Hotstuff work, cover view changes, pipelining, responsiveness and some other details.
On the last day of the previous decade, we published a paper called Doomslug in which we proposed a new way of producing blocks that allows us to achieve some sense of practical finality after just one round of communication, with a finality gadget providing full BFT finality after the second round.
What we refer to as practical finality, or doomslug finality is that a block produced by Doomslug is irreversible unless at least one participant is slashed. Doomslug also has a nice property that it continues producing and finalizing blocks for as long as just over half of all the participants are online and honest, not ⅔ as required by BFT consensus algorithms (though the finality gadget of course stalls if less than ⅔ of participants are online).
Now that the Doomslug implementation in NEAR is completed, it is a good time to discuss how it works, and how it compares to other approaches. Specifically, we will compare it to Tendermint and HotStuff.
If you have questions while you read, feedback is encouraged. Ask your questions and join the discussion here.
How Doomslug works
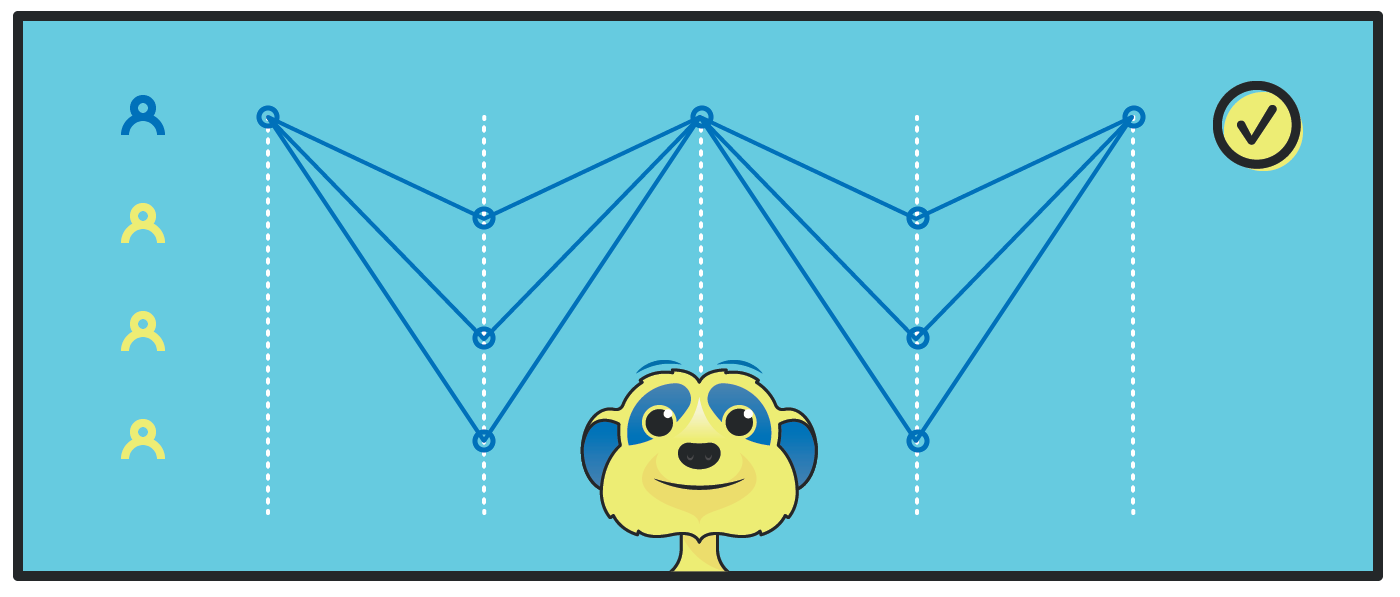
In short, Doomslug works by having a set of participants take turns to produce and broadcast blocks. Once a block at height h is received by other participants, they send endorsements on such a block to the participant assigned to the next height h+1. If after some predetermined time the participant assigned to h+1 hasn’t produced a block, the participants who sent an endorsement to her send another message to the participant assigned to h+2 indicating that they suggest skipping the block at h+1.
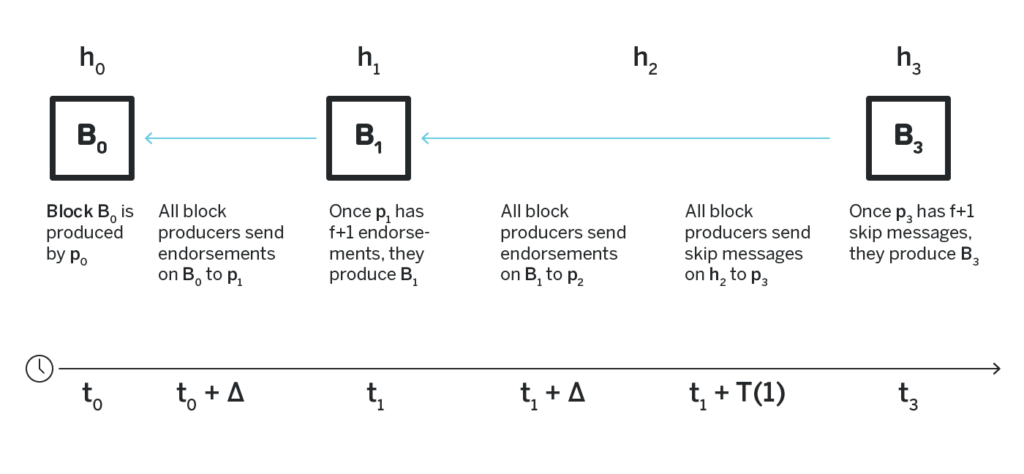
Once a participant has endorsements or skip-messages from more than half of other participants, they can produce their block.
With careful handling of message delays and exact slashing conditions, this rather simple technique can provide the property that we discussed above: if a block produced by Doomslug contains endorsements on the previous block from more than half of the block producers, the previous block is irreversible unless at least one of the block producers is slashed. Moreover, it is guaranteed that even if the network is slow, and messages are delayed, a block that contains endorsements from more than half the block producers will be created at some point, so the algorithm never stalls.
As mentioned above, there’s a finality gadget that operates together with Doomslug. Under normal circumstances once a block at height `h+1` is produced, and the block at height `h` has doomslug finality, the block at height `h-1` will have a full BFT finality. In other words, at least ⅓ of the total stake would need to be slashed to revert it. We will see how it compares to other consensus algorithms two sections below.
Both Doomslug and the finality gadget guarantees around blocks irreversibility do not make any assumptions about how slow or reliable the network is. In other words, both Doomslug and the finality gadget have safety under asynchronous network assumption. However, the guarantee that they cannot stall (a property called “liveness”) assumes a partially synchronous network. It is a rather common assumption, and all the consensus algorithms discussed in this post make this assumption in their liveness proofs. Having both guaranteed safety and liveness under asynchronous network is impossible, a limitation known as FLP impossibility.
A Short primer on PBFT, Tendermint, and Hotstuff
Before we dig into the comparison of Doomslug with Tendermint and Hotstuff, let’s do a quick review of how they work.
In a good case PBFT, Tendermint and Hotstuff all work in a very similar manner:
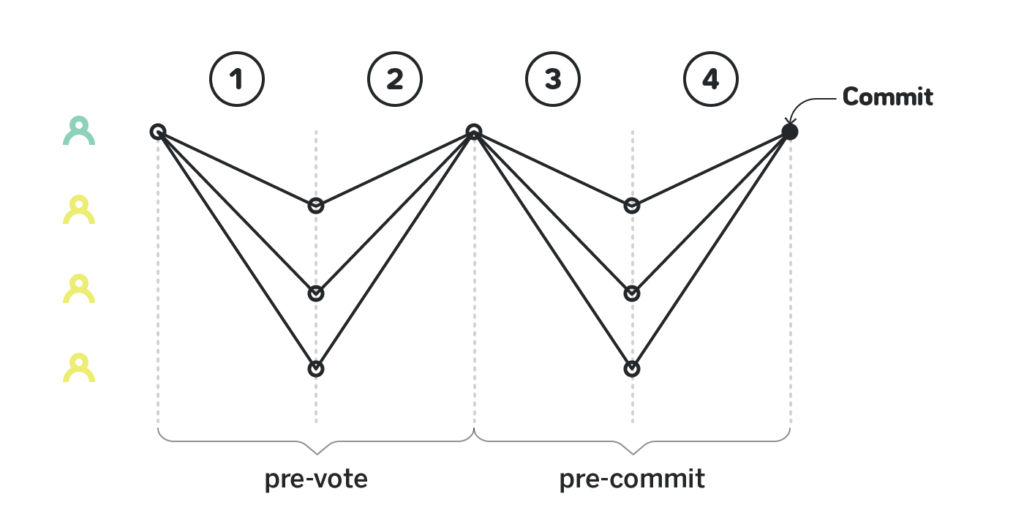
The consensus protocol happens over multiple views, optimistically in just one view. In each view there’s a particular leader who is assigned to carry out the consensus. The leader proposes a particular outcome. In the first view the choice of outcome is arbitrary. The leader sends the proposed outcome to all the remaining participants, and they send back their pre-vote on the outcome. The participants wait until there are pre-votes on the outcome from ⅔ of them, and then each participant sends a pre-commit on the outcome. Once there are pre-commit messages from ⅔ of participants, the consensus is reached.
The way the participants exchange messages differs between protocols. In Tendermint the participants use the gossip protocol, and each participant accumulates the pre-vote and pre-commit messages locally, while in Hotstuff the leader accumulates messages and sends them back.
The entire process can be made with just a linear amount of network overhead. Indeed, if the leader accumulates the pre-votes and pre-commits, then the initial broadcast of the proposed outcome, as well as other participants communicating back their pre-votes and pre-commits is already linear. The only quadratic overhead naively is sending accumulated pre-votes and accumulated pre-commits, but this can be done with linear overhead as well, if the accumulated messages are compressed using e.g. BLS signatures.
If for any reason the leader fails to carry out the consensus, it moves to the next view, in which the next leader will attempt again. The view change is where Hotstuff and Tendermint differ significantly from PBFT. In PBFT each participant has a timer that measures how much time has passed since the beginning of the view, and once the timer crosses a certain threshold, they send a view-change message to the next leader. The next leader needs to accumulate the view-change messages from ⅔ of the participants and send back a new-view message to them. This entire procedure requires at least cubic network overhead, and is also rather hard to implement correctly.
Tendermint and Hotstuff handle the view changes differently. Instead, there are timeouts in each phase (pre-vote and pre-commit), and whenever such a timeout is triggered, the participant sends a corresponding pre-vote or a pre-commit on nil, and moves to the next phase or view locally. Thus, the view-change is not an orchestrated process, and is rather implicit. Importantly, the mechanism for the view-change and for committing the block is essentially the same, which significantly simplifies the algorithm.
There are two major differences between Tendermint and Hotstuff. One is that Hotstuff is pipelined, meaning that a pre-commit of one view is a pre-vote for the next one, requiring almost twice as few phases as a non-pipelined version. There are proposals to make Tendermint pipelined, but the way it is implemented in Cosmos and presented in the paper are not pipelined. Second, and more frequently discussed, the difference is the fact that Hotstuff has so-called responsiveness, in other words, that an honest leader will always have the consensus reached in time bounded by the network delays, not timeouts. In Tendermint it is not the case, because in the pre-commit phase if a participant observes pre-commits on nil from ⅔ of the participants, they cannot move to the next view until the timeout expires, otherwise, an adversary with careful control of the network can make the algorithm switch between views indefinitely.
The responsiveness, while a neat feature, is somewhat misleading. Specifically, it only guarantees that the time it will take for the consensus to be reached will be bound by network delays if the leader is online and honest. If the leader is offline, the system will still wait the full timeout to move to the next view. In practice in Cosmos, which has been running a large instance of Tendermint for a long time presently, all the view-changes that ever occurred were due to the offline leader, and never due to the pre-commit on nil, thus the responsiveness of Hotstuff would have never mattered in Cosmos up to date.
I’m also not diving deep here into the fact that Hotstuff requires an extra round of communication to achieve responsiveness. In the first view, such an extra round can be omitted, and in the second view it is compensated with pipelining, thus the extra round rarely becomes an issue.
Doomslug vs Tendermint and Hotstuff
The optimistic case
Now let’s compare how Doomslug with a finality gadget compares to Tendermint and Hotstuff under various conditions. First, let’s consider the case in which no view-changes occur, and all the messages reach the leaders in time.
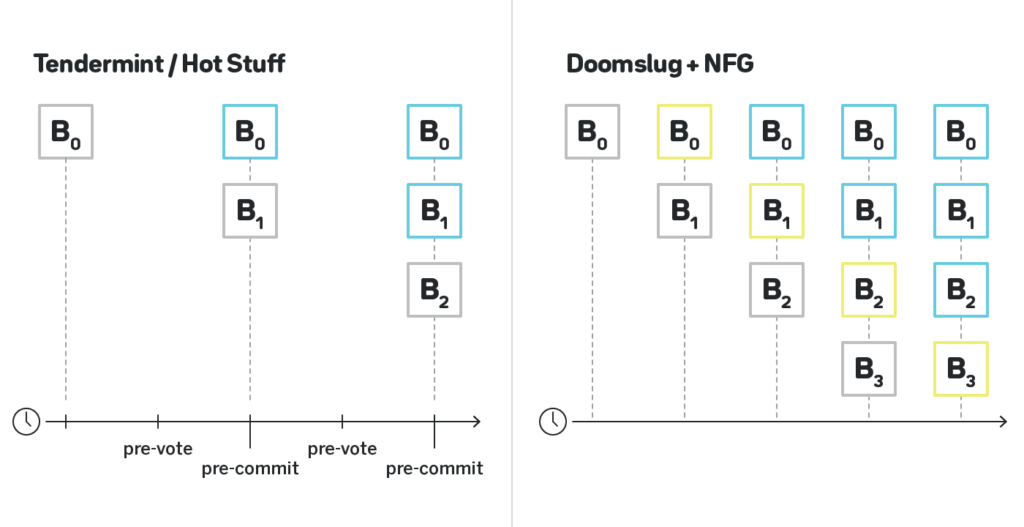
In the figure above, grey blocks are proposed blocks, blue blocks are blocks that have BFT finality, and yellow blocks are blocks that have doomslug finality.
Under normal circumstances Hotstuff and Tendermint behave exactly the same way: after a block is proposed, within two rounds of communication the block is final, and after two more rounds the block that immediately follows it is also final. Note that Hotstuff doesn’t pipeline across blocks, only across views, and thus producing two blocks still requires four rounds, not three.
Doomslug doesn’t improve on latency to full BFT finality, and thus since the moment the first block is produced, it still takes two rounds of communication until it has the full BFT finality. As discussed above, however, after the first round of communication the block already has a weaker than BFT sense of finality that we refer to as “doomslug finality”, in other words, it is irreversible unless at least one block producer is slashed.
Also note that by nature of finality gadgets, their throughput is the same as the underlying block production, and thus after three rounds of communication there are already two blocks that have full BFT finality, and after four rounds there are three such blocks. In other words, while it takes the same time for Doomslug with the finality gadget to reach full BFT finality on a single block, it finalizes twice as many blocks as Tendermint or Hotstuff per long period of time. While it doesn’t improve on latency, it improves the throughput by a factor of two.
The less optimistic case
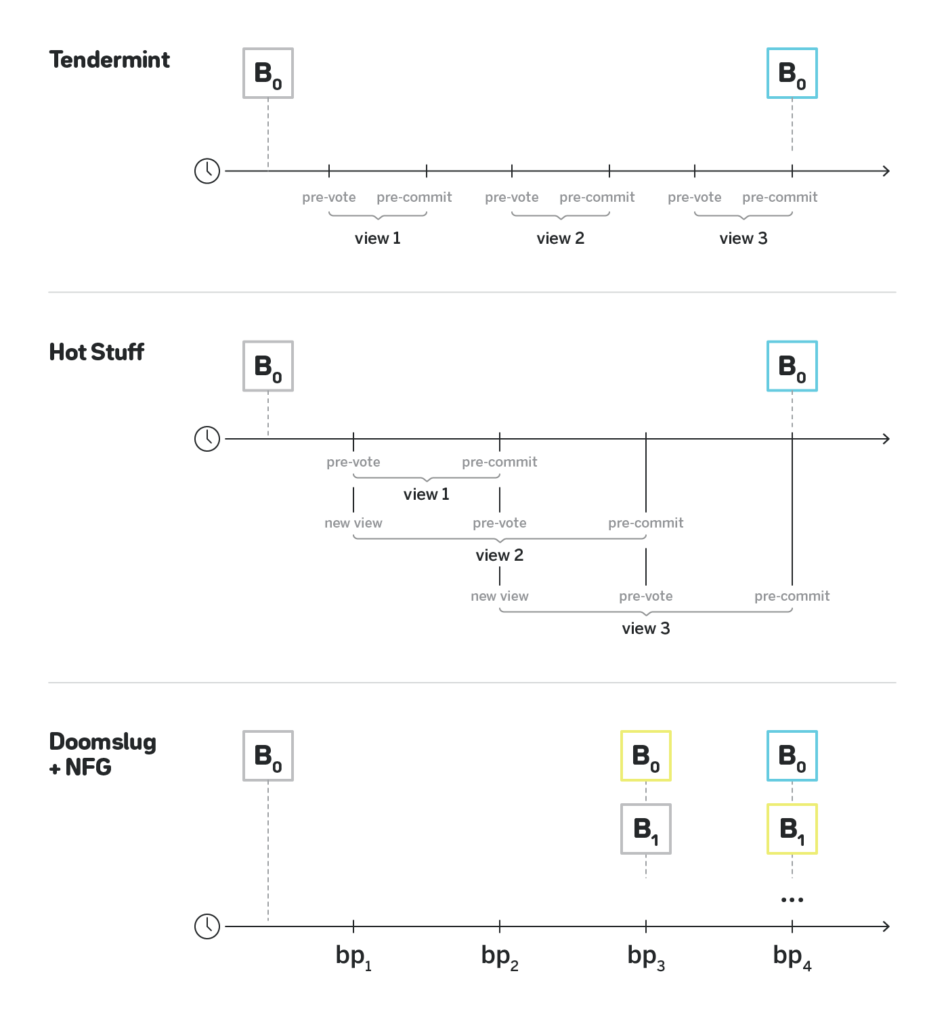
Now let’s see what happens in a less optimistic case, in which either some participants are offline, or a view fails for another reason. In the figure above, we show the case in which two consecutive views have failed. In the case of Tendermint, each failed view adds two rounds of communication, and thus it will take six rounds of communication to finalize a block. In the case of Hotstuff, the pipelining kicks in, and the block will be finalized after just four rounds of communication. Due to finality gadgets having the same throughput as the underlying block production, Doomslug with the finality gadget enjoys the same pipelining, and will also finalize the block after four rounds of communication. It is the case, however, that after the first three rounds the block will already have “doomslug finality”, and after the fourth round together with the first block reaching BFT finality, a block built on top of it will already have doomslug finality as well.
Other considerations
Above we covered one dimension on which block production and consensus algorithms can be compared: the number of rounds to finality under different conditions. There are other considerations. For example, while all the consensus algorithms discussed in this post have liveness (in other words are guaranteed not to stall under certain practical conditions), their exact behavior in presence of network delays and interruptions differs. The amount of time it takes to recover after a period of long loss of connectivity can vary noticeably. Our simulated tests show that Doomslug recovers quickly after long periods of network inactivity (the simulation code can be found here), but generally, very little research was done on comparing the consensus protocols from this perspective.
Another dimension is implementation complexity. With an assumption that ⅓ of all the block producers, weighted by stake, can never become corrupted, a protocol built on Tendermint or Hotstuff doesn’t need to implement any logic to handle forks. Doomslug finalizes blocks slower than it produces them, and therefore forks are possible until the blocks are actually final. Correspondingly, the protocol needs to be able to handle such forks, which noticeably increases the complexity of the implementation. In case of NEAR, we switched to Doomslug from a flavor of longest chain protocol, and thus already had all the logic of handling forks and an intensive test coverage for it implemented, but for a new effort to build a protocol not having to deal with forks can result in a considerable reduction of implementation cost.
Outro
Check out our Whiteboard Series with NEAR, in which we talk to the founders and core developers of other protocols, such as Ethereum Serenity, Cosmos, Polkadot and many others, and dive deep into the details of their technology. All the video episodes are conveniently assembled into a playlist here.
NEAR Protocol is an infrastructure for open web and a sharded blockchain protocol. You can learn more about our technology in our sharding design paper, through deep-dive videos, or by exploring our Rust reference client implementation.
Follow @NEARprotocol on Twitter to get notified about new content we post, and get the latest updates on the development of the protocol.
If you want to get involved, please join the conversation here!
Thanks to Zaki Manian and Ethan Buchman from Tendermint for reviewing an early draft of this post and providing feedback!
Share this:
Join the community:
Follow NEAR:
More posts from our blog


