How do Randomness Beacons based on Threshold Signatures work?
Introduction
Back in 2015, DFinity made the community extremely excited with their design of a randomness beacon that was leveraging BLS threshold signatures to produce a randomness output that is both unbiased and unpredictable.
As of 2020 building an unbiased and unpredictable randomness beacon remains extremely challenging, and very few protocols have one live. Threshold signatures are not the only proposed approach, and we previously published a short overview of various other approaches to randomness, including an approach that we considered back then in this blog post. Refer to it for the details on what the randomness beacon is, what it means to be unbiased and unpredictable, and what approaches besides threshold signatures were proposed.
After multiple iterations of design, we ultimately ended up building something very similar to what DFinity uses, and that is a great opportunity to dive deep into how such randomness beacons work.
In this article, we will describe the complex protocol of using threshold signatures to generate random numbers in very simple terms. Let’s dive in!
Crypto Fundamentals
For the purpose of understanding randomness beacons in this article, we will need to understand some very basic cryptography. We need to differentiate between two concepts: scalars, or just regular numbers, which throughout this article we will denote with lowercase letters (e.g. x, y) and elliptic curve points, which we will denote with uppercase letters.
We don’t need to understand much about elliptic curve points, besides a few properties:
- Elliptic curve points can be added together, and an elliptic curve point can be multiplied by a scalar (we will denote it as xG, though a notation Gx is also very common). The result of both operations is another elliptic curve point.
- Knowing G and xG it is computationally infeasible to derive x.
We will also be using a concept of a polynomial p(x) of degree k-1. For the purposes of this article it is sufficient to think about it as a function p(x) such that if one knows the value of p(x) at any k distinct values of x, they can also derive p(x) at any other x as well.
Interestingly, for the same function, and some elliptic curve point G, if one knows the value of p(x)G at any k distinct values of x, they can also derive p(x)G at any other x.
Those are the only properties of elliptic curve points we will need to understand on the high level how randomness beacons work.
The Randomness Beacon
Say there are n participants, and say we want to require that it takes at least k of them to generate a random number and that an adversary that controls up to k-1 of the participants cannot predict the output of the randomness beacon, and cannot influence it in any way.
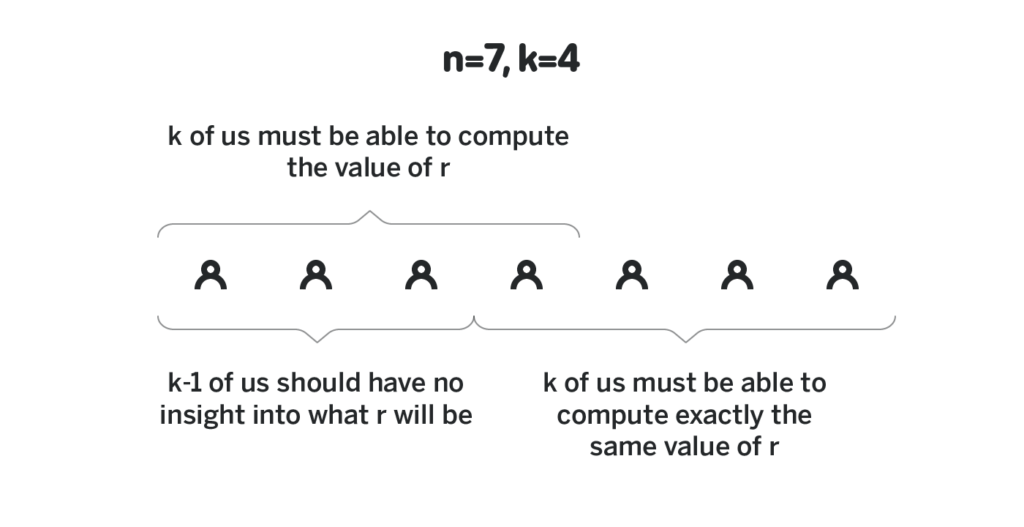
Say there exists some polynomial p(x) of degree k-1 such that the first participant knows p(1), the second participant knows p(2), and the n-th participant knows p(n). Also, say that for some agreed-upon elliptic curve point G everybody knows p(x)G for all values of x. We will call p(i) a private share of participant i (because the only participant i knows it), and p(i)G public share of participant i (because everybody knows it). Recall from the previous section that the knowledge of p(i)G is not sufficient to derive p(i).
Generating such a polynomial in a way that each participant knows their private share, but has no insight into the private shares of other participants is the most complex part of the randomness beacon, and is what is called Distributed Key Generation. We will cover it in the next section. For now, let’s assume such a polynomial exists, and all the participants know their shares.
Let’s see how to use it to have a randomness beacon in the context of a blockchain protocol. Say a block with hash h is produced, and the participants collectively want to generate a random number seeded by h. The way they proceed is first to use some agreed-upon function to convert h into an elliptic curve point:
H = scalarToPoint(h)
Then each participant i computes H_i = p(i)H, which they can do because they know p(i) and H. Revealing H_i will not reveal their private share, so the same private shares can be reused for each block, thus the DKG only needs to be performed once.
When at least k participants revealed their shares H_i = p(i)H, everyone can reconstruct any share H_x = p(x)H for any x due to the third property in the previous section. At this point, each participant can locally compute H_0 = p(0)H, and use the hash of it as the randomness beacon output. Note that since no participant knows p(0), the only way to compute p(0)H is to interpolate p(x)H, which is only possible if at least k of p(i)H were revealed. Revealing any smaller number of p(i)H gives no insight into the value of p(0)H.
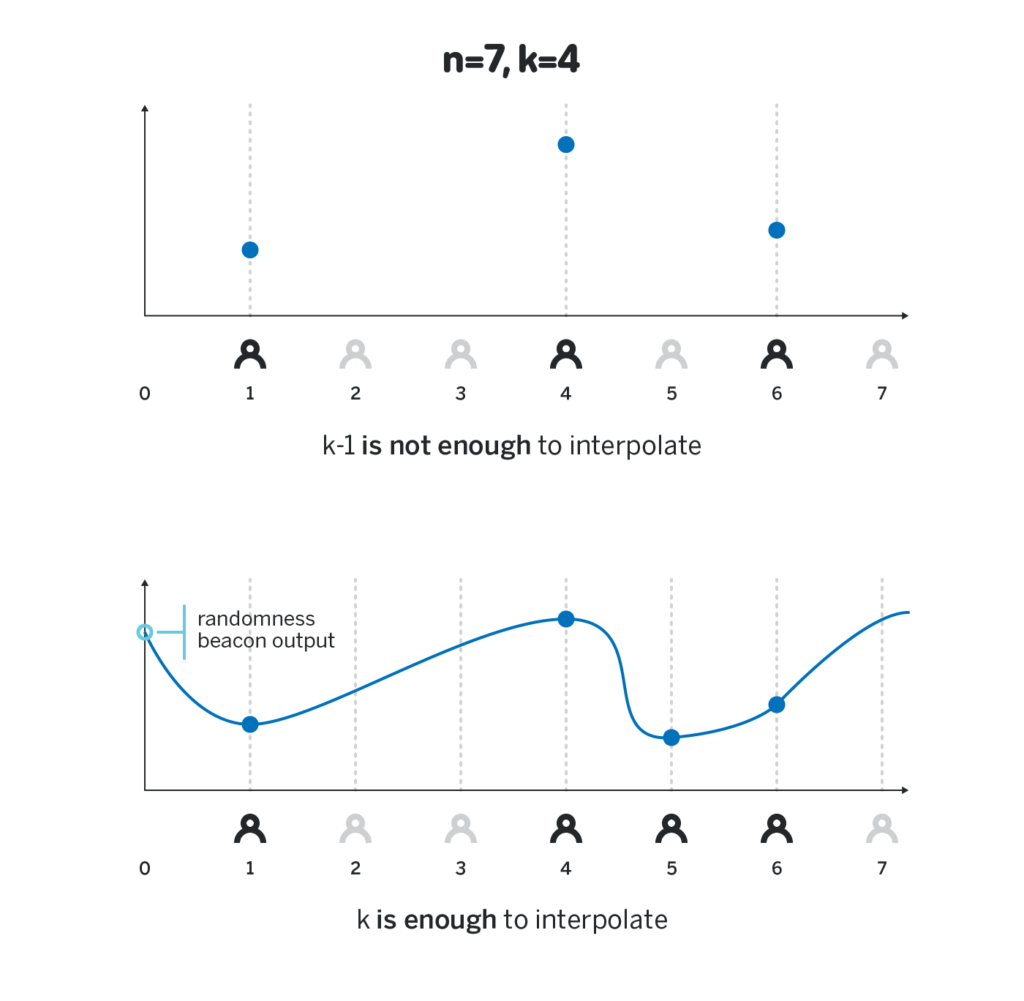
The beacon above has all the properties we desire: an adversary controlling k-1 or fewer participants cannot get any insight into the final output of the randomness beacon, while any k participants can compute the final output, and any subset of k or more participants will always arrive at the same value.
There is one issue we ignored above. For the interpolation to work, we need to make sure that the value H_i that the i-th participant revealed is indeed equal to p(i)H. Since no other participant knows p(i), they cannot naively verify that H_i is indeed correct, and without some cryptographic proof alongside H_i a malicious actor can reveal arbitrary value, and other participants will have no way of detecting it.
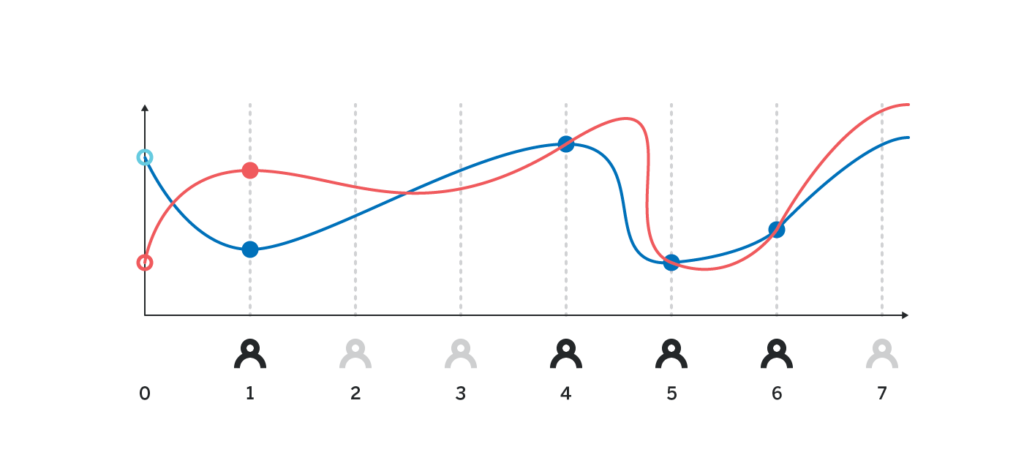
There are at least two ways to provide a cryptographic proof of H_i being correct, we will cover both of the two sections below after we talk about DKG.
Distributed Key Generation
For the randomness beacon in the previous section to work, we needed n participants to collectively come up with a polynomial p(x) of degree k-1 such that each participant i knows the value of p(i), but no other participant has any insight into that value. For the constructions in the next section, it will also be necessary that all the participants know p(x)G for some agreed-upon G and all x.
Throughout this section, we assume that every participant has some private key x_i associated with them, and all the participants know the public key X_i that corresponds to such a private key.
One way to go about DKG is then the following:
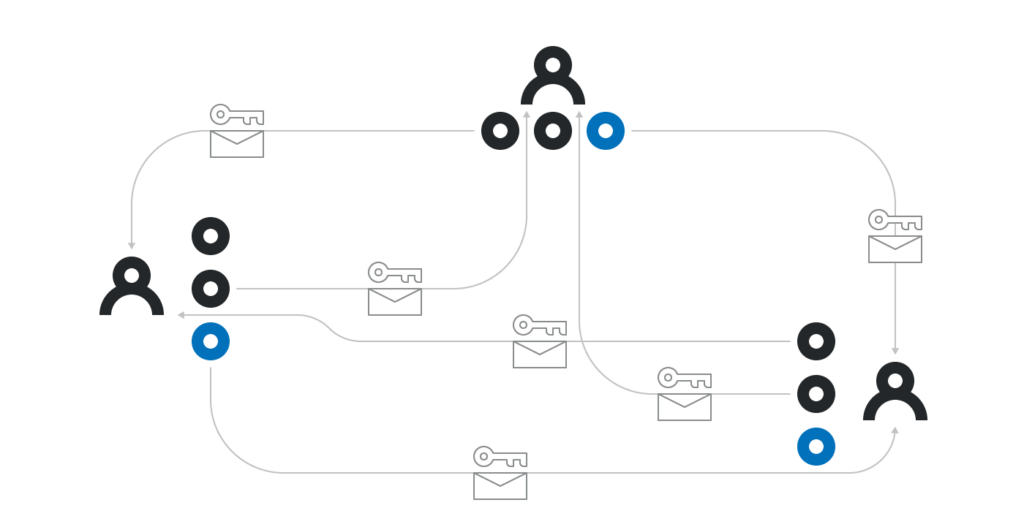
- Each participant i locally computes some polynomial p_i(x) of degree k-1. They then send p_i(j) to each participant j encrypted with the public key X_j, so that only j-th participant can decode p_i(j). Participant i also publicly announces p_i(j)G for all j from 1 to k inclusive.
- All the participants collectively agree on some set of at least k such committed polynomials. Since some participants can be offline, they can’t wait until all n of them commit, but once at least k have committed, they can use any sort of consensus algorithm (for example Tendermint) to agree on some subset Z of at least k polynomials.
- The participants collectively verify that the encrypted p_i(j) corresponds to the publicly announced p_i(j)G. The polynomials for which it is not the case are removed from Z.
- Each participant j computes their private share p(j) as the sum of p_i(j) for each i in Z. Each participant can also compute each public share p(x)G as the sum of p_i(x)G for each i in Z.
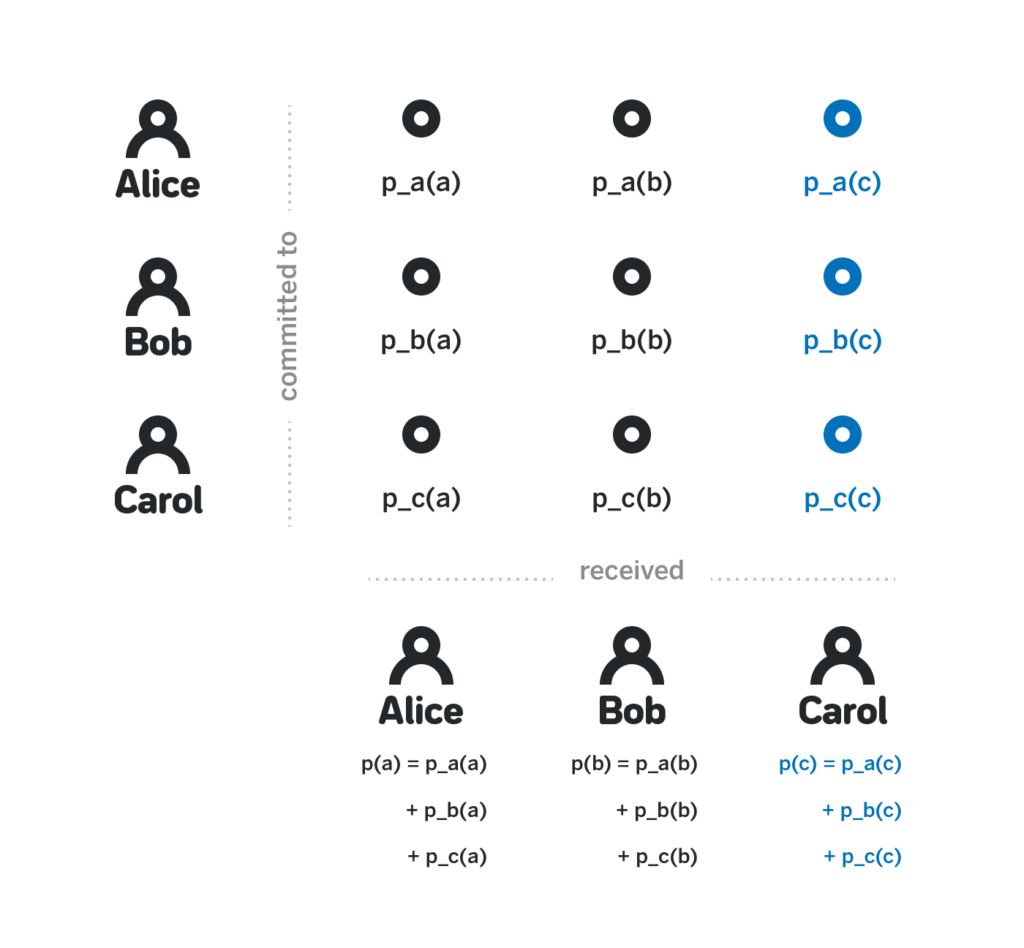
Observe that p(x) is indeed a polynomial of degree k-1, because it is the sum of individual p_i(x), each of which is a polynomial of degree k-1. Then, note that while each participant j knows p(j), they have no insight into the values of other p(x) for x ≠ j. Indeed, to know such a value they’d need to know all p_i(x), and for as long as the participant j doesn’t know at least one of the committed polynomials, they don’t have any information about p(x).
This constitutes the entirety of the DKG process. Steps 1, 2 and 4 above are relatively straightforward. Step 3 is where DKG gets tricky.
Specifically, we need some way to prove that each encrypted p_i(j) indeed corresponds to the publicly broadcasted p_i(j)G. Without a way to verify it, an adversary i can send some gibberish information to participant j instead of actually encrypted p_i(j), and participant j will have no way to compute their private share later.
There’s a way to create a cryptographic proof of the correctness of the encrypted share. However, the size of such a proof is prohibitively large, and given that O(nk) such proofs need to be published, the size of the proof becomes a bottleneck.
Instead of proving cryptographically that p_i(j) corresponds to p_i(j)G in NEAR we instead allocate a lot of time during DKG between the moment the set of polynomials is agreed upon and the moment the final shares are aggregated, during which each participant can provide a cryptographic proof that the encrypted share p_i(j) sent to them doesn’t correspond to the publicly broadcasted p_i(j)G. It makes an assumption that each participant will go online at least once during that time frame (which spans approximately half a day), and that the challenge they submit will make it to the blockchain. In the case of block producers, both assumptions are rather realistic, since the block producers are expected to remain online throughout the epoch, and for a message to be censored majority of block producers need to collude and not include it in their blocks, in which case they have significantly more profitable ways to attack the system.
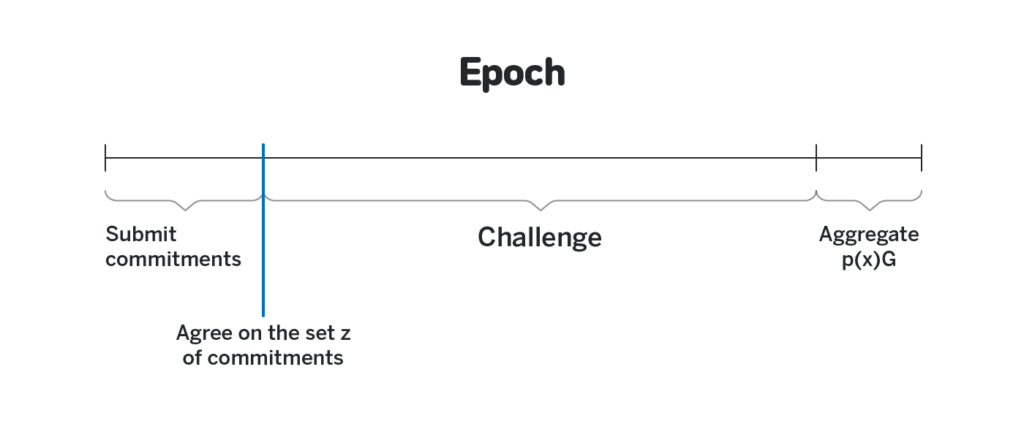
If a particular block producer does receive an invalid share and then fails to show up during DKG and challenge it, they will not be able to participate in generating random numbers during the same epoch. Note that for as long as k other honest participants have their shares (by either not receiving any invalid shares, or challenging all the invalid shares in time), the protocol will still function.
Proofs
The last part of the randomness beacon that is still left uncovered is how one can prove that a published value H_i is equal to p(i)H without revealing p(i).
Recall that the values H, G, p(i)G are all known to everybody. The operation that computes p(i) given p(i)G and G is called discrete logarithm, or dlog for short, and what each participant wants to prove to others is that
dlog(p(i)G, G) = dlog(H_i, H)
Without revealing p(i). Constructions for such proof do exist, one such construction is called Schnorr Protocol.
With such a construction, whenever a participant submits H_i, they also submit proof of correctness of H_i.
Recall that the final randomness beacon output is the interpolated value of H_0. What information needs to be distributed along with H_0 for external participants that didn’t participate in the generation of it to be able to verify its correctness? Since everybody can locally interpolate G_0, a proof that
dlog(G_0, G) = dlog(H_0, H)
would suffice, but we cannot use the Schnorr Protocol to create such a proof since it requires the knowledge of p(0), and the randomness beacon relies on nobody knowing the value. Thus, one needs to keep all the values of H_i along with the corresponding proofs to prove the correctness of H_0 to external observers.
However, if there was some operation that semantically resembled multiplication on elliptic curve points, proving that H_0 was computed correctly would become trivial, by just verifying that
H_0 × G = G_0 × H
If the chosen elliptic curve supports so-called elliptic curve pairings, such a proof becomes possible. In such a case H_0 not only serves as an output of the randomness beacon that can be trivially verified by anyone who knows G, H and G_0 but also it serves as a collective multi-signature that attests that at least k out of n block producer signed the block.
We do not use elliptic curve pairings in NEAR today, though we might use them in the future, and then the neat trick discussed above would replace the individual signatures we use today. DFinity, on the other hand, uses BLS signatures and can leverage the pairings to make such multi signatures work.
Outro
The implementation of the randomness beacon is mostly complete in our reference client implementation (see this commit), however, the first version of the NEAR Protocol will likely launch without it, to allow more time for stabilization of the beacon. Once it is shipped, however, all the contracts on NEAR will enjoy access to unbiasable and unpredictable random number generator, which enables many uses cases not possible today on other networks.
The first release of the NEAR Protocol will use a significantly simpler randomness beacon (see this pull request), where the random value is just the output of a verifiable random function on the previous output of the random beacon by the current block producer. Such a randomness beacon is unpredictable, but is not unbiasable: the current block producer has one bit of influence because they can choose not to produce a block. It happens to be very similar to the randomness beacon that Ethereum 2.0 will use before they have the VDFs beacon available (the randomness output is the VRF by the current block producer on the epoch hash), and is also the way the randomness beacon works in Elrond.
If you are interested in how blockchain protocols work, check out our Whiteboard Series with NEAR, in which we talk to the founders and core developers of other protocols, such as Ethereum Serenity, Cosmos, Polkadot and many others, and dive deep into the details of their technology. All the video episodes are conveniently assembled into a playlist here.
NEAR Protocol is an infrastructure for the open web and a sharded blockchain protocol. You can learn more about our technology in our sharding design paper, through deep-dive videos, or by exploring our Rust reference client implementation.
Follow @NEARprotocol on Twitter to get notified about new content we post and get the latest updates on the development of the protocol
If you want to get involved, please join the conversation here!
Share this:
Join the community:
Follow NEAR:
More posts from our blog


